Linux 性能分析 - 上下文切换
(Linux 性能分析, Part 2)
前言
上一篇文章中提到,处于可运行状态的进程越多,平均负载也越高。
有人可能会有疑问,这种计算方法合理吗?同样是 100% 的 CPU 使用率,有 10 个可运行进程的系统的平均负载,是有 1 个可运行进程系统的负载的 10 倍?本文就试图从 CPU 上下文切换的角度来解释这一指标的合理性。
上下文切换定义
CPU 上下文切换
虽然系统的 CPU 个数有限,但能支持同时运行个任务。当然这种同时只是宏观上的假象,如果从微观角度观察,会发现系统在不停轮流切换任务,使得每个任务都能获得运行的机会。
CPU 是状态 + 存储的模型,其符合图灵机这种理想设备:
- 内存
- PC 指针指向下一条待运行的指令(状态)
- 计算规则
- 其他辅助计算的寄存器(状态)
多任务的每个任务都有自己的状态。当任务 1 切出,任务 2 切入时,CPU 的状态也要切换成任务 2 上一次切出时的状态,这样任务 2 才能继续运行。这些状态即是 CPU 上下文,CPU 上下文切换即保存和恢复 PC 和辅助计算的寄存器。
进程上下文切换
CPU 中的寄存器似乎一只手就数的过来,切换的成本非常小,为什么会造成系统负载显著升高呢?Linux 操作系统中的任务有进程和线程,切换的主要成本来自于进程/线程的上下文切换。
第一点,现代处理器有很多个运行等级。比如在 x86 的保护模式中,有四种特权等级。Linux 使用 Ring 0 和 Ring 3:
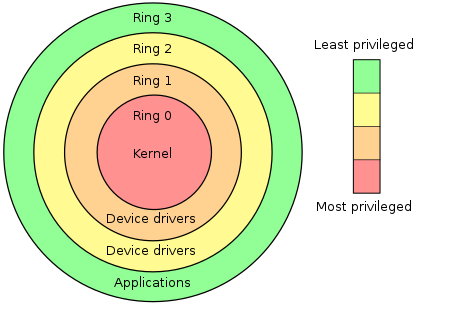
- Ring 0 是内核空间,具有最高权限,可访问所有硬件资源
- Ring 3 是用户空间,权限最低,无法直接访问硬件资源
用户态权限有限,无法直接操作所有寄存器,进程的切换只能由内核态来管理和调度,所以必然发生用户态 <-> 内核态的频繁转换。而每个特权等级运行的代码不同,所以在切换用户态 <-> 内核态时,内核/用户空间本身的 CPU 上下文也需要互相切换。
第二点,进程本身的数据结构庞大。Linux 中使用数据结构 task_struct 来描述进程所有的资源,其主要成员有进程状态、内核栈信息、进程使用状态、PID、优先级、锁、时间片、队列、信号量、内存管理信息、文件列表等等与进程管理、调度密切相关的信息。当切换进程运行,这些数据结构也需要保存和恢复。
第三点,虚拟内存。内核为每个进程提供了一个假象:进程都是独占地使用内存,这种独占是无法感知也无法使用其它进程的内存。
虚拟内存和实际的物理内存之间映射不是一个地址一个地址的映射,而是通过页表机制来实现。一页通常是 4096KB,这样的映射关系即为页表数据,为了减少页表数据的大小,会采用多级页表,比如 Linux 为了让进程支持 256T 内存,采用了四级页表。页表机制会带来额外的问题,页表本身也是存在内存里的,四级页表最坏情况下需要 5 次内存 IO 才能获取一个真正的内存数据。
为了让操作系统更快地操作虚拟内存,x86 处理器专门提供了 TLB(Translation Lookaside Buffer) 来管理虚拟内存到物理内存的映射关系。它可以理解为一个专用缓存,特点就是快,但缺点是存储的数据少,缓存有可能不命中。当系统发生进程切换,从进程 A 切换到进程 B,TLB 也必须刷新,那在刷新后,进程 B 必然会出现 TLB 不命中的情况,导致虚拟内存访问变慢。
由以上三点可见,进程上下文切换开销巨大,根据 Tsuna的测试报告,这一过程会持续数千纳秒。如果进程切换频繁,系统真正运行进程的时间便不够了。
线程上下文切换
在 Linux 的实现中,系统调度的基本单位其实是线程,进程是线程的集合,同一个进程的线程看到的虚拟内存是共享的,所以:
- 如果切换的两个线程分属不同的进程,因为资源不共享,其切换成本等同于进程上下文切换。
- 如果切换的两个线程属于同一个进程,因为虚拟内存是共享的,刷新 TLB 没有必要,切换成本也就少。
中断上下文切换
为了快速响应硬件事件,Linux 中发生中断也会打断进程的正常执行,这时候就会发生中断上下文切换。
中断程序执行于内核空间,与任何进程无关,故用户态进程程序切换到中断处理程序时,没有虚拟内存切换的成本,保持 TLB 不变即可。
上下文切换的时机
切换分两种,自愿和非自愿:
- 自愿上下文切换(voluntary context switches)。比如当前进程所需资源未满足时,便会挂起等待。又比如调用睡眠函数 sleep 这样的方法将自己主动挂起。
- 非自愿上下文切换(non voluntary context switches)。操作系统为保证调度的公平性,会将时间分片,轮流分给每个进程。进程若在自己的时间片内未执行完,便会被系统强制切出 CPU。Linux 系统还支持带优先级的进程,高优先级进程可以打断低优先级进程。
有一点需要强调,虽然用ps aux能看到数百个进程,但并非意味着 Linux 需要在这数百个进程上切换。它们大部分处于睡眠状态,操作系统只会对处于可运行态的进程间作上下文切换。
实验
工具
vmstat 命令帮助文档虽然说是 Report virtual memory statistics,但其实它还能统计 CPU/中断/IO/缺页等使用情况。
以下是该命令每隔 1 秒输出一次统计数据,输出 10 次(第一次的输出不可信):
➜ ~ vmstat 1 10
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 524 2010216 1195432 10930004 0 0 0 50 1 2 4 2 92 3 0
...
我们需要关心的是:
- r,可运行进程的个数(运行和就绪的进程)
- b,不可中断进程的个数
- in,每秒中断次数,包括时钟
- cs,每秒 CPU 上下文切换次数
- us,执行用户代码的时间
- sy,执行内核代码的时间
vmstat 命令还不够,上一篇文章中介绍的 pidstat 可以看到进程上下文切换的数据:
➜ ~ pidstat -w 5
Linux 4.15.0-96-generic (work) 06/20/2020 _x86_64_ (2 CPU)
11:46:00 PM UID PID cswch/s nvcswch/s Command
11:46:05 PM 0 1 1.00 0.00 systemd
11:46:05 PM 0 7 12.38 0.00 ksoftirqd/0
11:46:05 PM 0 8 132.93 0.00 rcu_sched
11:46:05 PM 0 11 0.20 0.00 watchdog/0
11:46:05 PM 0 14 0.20 0.00 watchdog/1
11:46:05 PM 0 16 12.97 0.00 ksoftirqd/1
11:46:05 PM 0 207 25.15 0.00 usb-storage
11:46:05 PM 0 209 7.98 0.00 kworker/0:1H
11:46:05 PM 0 330 2.00 0.00 jbd2/sda2-8
11:46:05 PM 0 333 0.40 0.00 kworker/1:1H
11:46:05 PM 0 436 2.00 1.00 systemd-udevd
...
其中:
- cswch/s,每秒自愿上下文切换次数
- nvcswch/s,每秒非自愿上下文切换次数
如果要看到线程上下文切换的信息,还需要加上 -t 参数:
➜ ~ pidstat -w 5 -t
Linux 4.15.0-96-generic (work) 06/20/2020 _x86_64_ (2 CPU)
11:50:28 PM UID TGID TID cswch/s nvcswch/s Command
11:50:33 PM 0 4588 - 0.20 0.20 pili-themisd
11:50:33 PM 0 - 4588 0.20 0.20 |__pili-themisd
11:50:33 PM 0 - 4589 13.44 0.20 |__pili-themisd
11:50:33 PM 0 - 4590 1.98 0.00 |__pili-themisd
11:50:33 PM 0 - 4594 3.75 0.00 |__pili-themisd
11:50:33 PM 0 - 4596 4.55 1.19 |__pili-themisd
11:50:33 PM 0 - 4650 3.95 0.40 |__pili-themisd
11:50:33 PM 0 - 4674 2.96 0.40 |__pili-themisd
...
进程和线程的实验
stress 进程切换实验
我们回到最开始的问题,为什么同样是 100% 的 CPU 使用率,有 10 个可运行进程的系统的平均负载,是有 1 个可运行进程系统的负载的 10 倍?
首先看一下 100% CPU,1 个可运行进程的上下文切换次数:
➜ ~ stress -c 1 -t 600
stress: info: [6800] dispatching hogs: 1 cpu, 0 io, 0 vm, 0 hdd
➜ ~ vmstat 1 20
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 294216 274960 2234876 0 0 0 24 2714 7362 54 1 45 0 0
2 0 0 294208 274960 2234876 0 0 0 68 2327 6601 59 2 39 1 0
2 0 0 294216 274960 2234880 0 0 0 116 1555 4465 53 2 45 0 1
➜ ~ pidstat -w 1
Average: UID PID cswch/s nvcswch/s Command
Average: 0 9258 0.00 64.39 stress
首先看一下 100% CPU,10 个可运行进程的上下文切换次数:
➜ ~ stress -c 10 -t 600
stress: info: [7024] dispatching hogs: 10 cpu, 0 io, 0 vm, 0 hdd
➜ ~ vmstat 1 20
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
10 0 0 294972 274976 2234964 0 0 0 28 2097 5976 99 2 0 0 0
13 0 0 294900 274976 2234976 0 0 0 176 2256 6545 98 2 0 0 0
10 0 0 295040 274976 2234976 0 0 0 28 2254 6835 99 1 0 0 1
➜ ~ pidstat -w 1
Average: UID PID cswch/s nvcswch/s Command
Average: 0 7025 0.00 160.97 stress
Average: 0 7026 0.00 125.14 stress
Average: 0 7027 0.00 136.82 stress
Average: 0 7028 0.00 162.62 stress
Average: 0 7029 0.00 121.83 stress
Average: 0 7030 0.00 170.89 stress
Average: 0 7031 0.00 114.99 stress
Average: 0 7032 0.00 130.54 stress
Average: 0 7033 0.00 165.38 stress
Average: 0 7034 0.00 163.51 stress
光看 CPU 上下文切换次数似乎差不多,但进程被动上下文切换次数明显上升。我们之前了解到,CPU 切换的成本较小,进程的切换成本最高,这就是系统负载升高的原因。
sysbench 线程切换实验
stress 命令只能模拟多进程的系统压力,模拟多线程需要 sysbench 工具。
运行以下命令模拟 10 个线程竞争:
➜ ~ sysbench --threads=10 --max-time=300 threads run
➜ ~ uptime
08:41:12 up 69 days, 5:33, 2 users, load average: 6.32, 6.32, 6.73
➜ ~ vmstat 1 20
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
8 0 0 292580 275072 2237844 0 0 0 28 15202 1234282 30 69 2 0 0
8 0 0 292332 275072 2237848 0 0 0 224 18851 1221323 31 68 1 0 1
8 0 0 292280 275072 2237848 0 0 0 28 16822 1177891 32 66 2 0 0
➜ ~ pidstat -w -t 1 (需要加上 -t,否则不会统计线程的切换信息)
Average: 0 - 11743 19613.96 96288.49 |__sysbench
Average: 0 - 11744 20440.57 93726.42 |__sysbench
Average: 0 - 11745 20680.38 99453.02 |__sysbench
Average: 0 - 11746 19855.47 89219.06 |__sysbench
Average: 0 - 11747 18738.49 97730.38 |__sysbench
Average: 0 - 11748 14536.04 99870.75 |__sysbench
Average: 0 - 11749 15928.11 103604.72 |__sysbench
Average: 0 - 11750 18082.26 94775.66 |__sysbench
Average: 0 - 11751 20995.66 89222.64 |__sysbench
Average: 0 - 11752 20588.30 94581.89 |__sysbench
在多线程下,每秒 CPU 上下文切换次数达到了近 120 万,任务的自愿和非自愿切换同时升高。当然系统负载自然也就高了。
两者的不同
同样是调度 10 个任务,stress 和 sysbench 为什么切换次数区别如此之大?可以从两方面解释:
第一、同一个进程的线程间切换成本小,切换的频率可以升高。
第二、sysbench 和 stress 模拟压力的方式不同:
➜ ~ sysbench threads help
sysbench 1.0.11 (using system LuaJIT 2.1.0-beta3)
threads options:
--thread-yields=N number of yields to do per request [1000]
--thread-locks=N number of locks per thread [8]
➜ ~ stress --help
`stress' imposes certain types of compute stress on your system
Usage: stress [OPTION [ARG]] ...
-c, --cpu N spawn N workers spinning on sqrt()
- sysbench 用线程同步方式 (lock) 和主动让出 CPU (yield) 来产生系统压力,属于自愿上下文切换,统计数据中自愿切换的次数非 0。
- stress 用 CPU 密集型操作 (求根 sqrt()) 来产生系统压力,属于非自愿上下文切换,统计数据中自愿切换的次数为 0。
结论
在 CPU 跑满,系统平均负载均很高的情况下,需要具体情况具体分析:
- 自愿上下文切换变多,说明被调度任务在等待资源,有可能发生了 IO 或任务间同步情况
- 非自愿上下文切换变多,说明被调度的任务被强制打断,任务在争抢使用 CPU
- 如果上下文切换次数离奇的高,说明有可能是多线程场景