随机数生成策略对集测性能的影响
(Ginkgo 使用笔记, Part 2)
前言
七牛的测试机房需要搬迁,在 CI 系统迁移之后,发现新机房的集测总是多花 5-10min。一开始没怎么注意,以为只是新机器网络、磁盘慢之类的原因。但深入看了集测日志后,却发现,多出来的时间集中在集测之始,那就有必要好好分析一下了。
Ginkgo 表面之下
本篇需要一些前置知识,可参考:Ginkgo 测试框架实现解析。
Ginkgo 作为 Go 语言中比较流行的集测框架,它其实有不少隐含行为,做优化时不得不知:
Ginkgo是两阶段,先执行Describe/Context代码,解析出用例树,然后执行It用例。Ginkgo并发是多进程模型,且每个进程都需要完整地执行第一阶段。只有第二阶段才在各进程内有区别。
基于这两点,我们合理猜测,着多出来的 5-10min 是阻塞在了用例树生成阶段。
分析过程
在本地调试单进程,其实也能发现轻微的阻塞,但阻塞时间并不长(5s 左右),若把并发加到了 20,阻塞时间指数级增加,出现了和 CI 机器一样的现象。(长期没关注这个问题和我们的开发习惯有关,写测试用例的时候很少会开多并发执行)
加上 --cpuprofile 参数再次多并发执行用例,得到性能图:
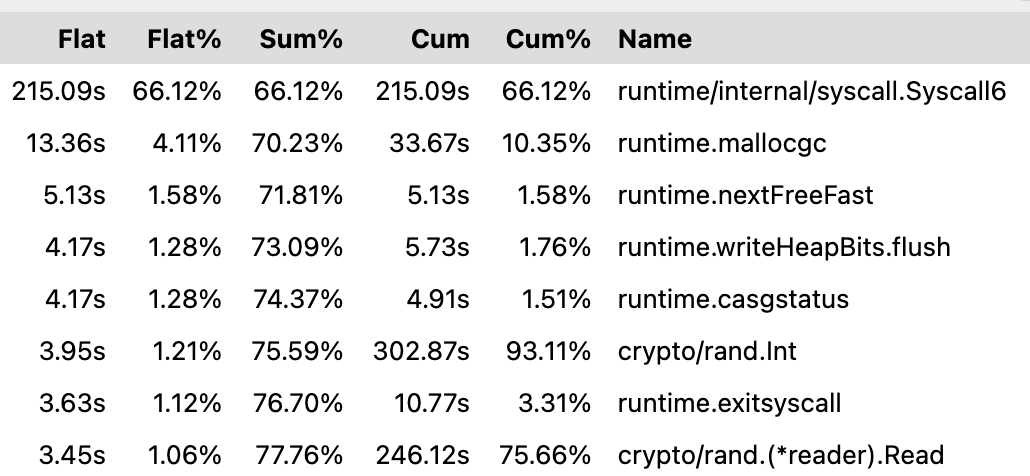
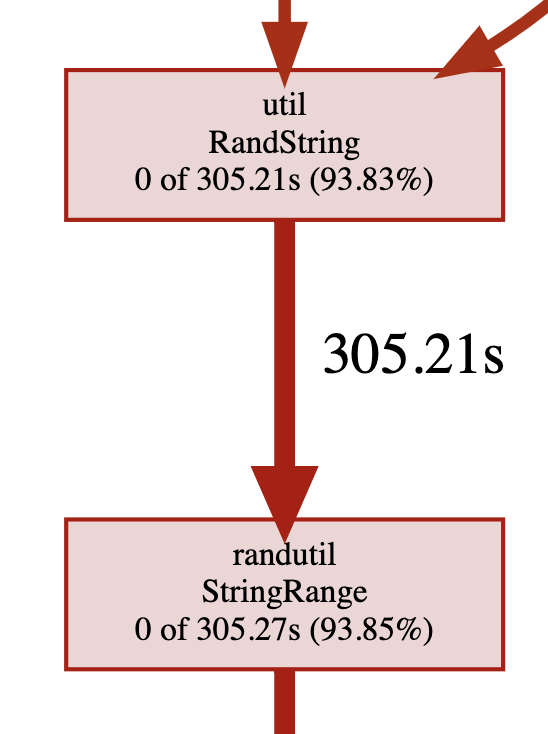
其中 randutil.StringRange 是第三方库,内部使用了 crypto/rand 来生成随机数,可以看到大部分性能被随机数生成吃掉了。为什么用例有这么多随机数?这和我们的云存储用例逻辑有关,其中需要创建随机命名的空间,上传随机命名的文件。
Go 有两种随机数生成函数:math/rand 和 crypto/rand。前者是纯数学方法生成的伪随机数,后者是通过系统调用 unix.GetRandom 获取:
func getRandom(p []byte) error {
n, err := unix.GetRandom(p, 0)
if err != nil {
return err
}
if n != len(p) {
return syscall.EIO
}
return nil
}
而第二个参数 0 意味着 GRND_RANDOM,以阻塞的方式读取 /dev/random 真随机值设备。该设备有一种叫熵的值代表可用的随机值,熵会来源于键盘、鼠标和磁盘 IO 等的数据,它的储备数量是有限的,生成速度也不快。在 Linux 上可以通过 /proc/sys/kernel/random/entropy_avail 查看熵。一旦无熵可用,进程便会阻塞。
破案结果
Ginkgo推荐在BeforeEach/BeforeAll中初始化变量,但七牛过去的用例书写并不规范,大量变量在定义时便被初始化。- 定义时初始化的变量会在每个并发的进程中被执行。(如果在
BeforeEach/BeforeAll中初始化,则只在需要的进程中执行) - 一个 20 字节长度的字符串,就需要执行 20 次随机数生成。
- 云存储累积了近 5000 个用例,每个用例约 20 个随机数,并发 20,那就需要 2000000 次随机数生成。
- 观察新机房机器上储备的熵,稳定在 4000 个左右。
所以,当我们的集测执行,进入第一阶段解析用例树时,随机数会被瞬间耗尽,然后阻塞在 unix.GetRandom 上。
这个问题可以说从很早就存在了,那为什么原来没发现呢?之前的机器已经不在了,只能猜测是之前的随机数生成比较快,所以没人注意。
解决
解决方法其实很简单,把 crypto/rand 换成 math/rand。