Linux 性能分析 - 如何理解系统平均负载
(Linux 性能分析, Part 3)
前言
之前的文章已经详细讨论了平均负载的含义,并尝试解释其合理性,现在我们来看一下大佬 Brendan Gregg 对该指标的看法。
本文大部分内容翻译、删减并理解自Linux Load Averages: Solving the Mystery。
第一篇文章,uptime 的 man 帮助文档有个未解之谜:为什么 Linux 上平均负载不仅关注可运行的任务,也关注不可中断睡眠状态的任务?我从未看到过官方的解释(也许有,但我没找到)。本文将解答这一问题,让每个开发者都能理解并运用这一指标。
Linux 的平均负载是系统平均负载,它显示的是系统对运行和等待线程(任务)数量的需求。既然这个指标是需求,那它有可能比系统正处理的任务数量多。大部分工具会显示三个数值,分别是 1 分钟,5 分钟和 15 分钟的平均负载:
$ uptime
16:48:24 up 4:11, 1 user, load average: 25.25, 23.40, 23.46
top - 16:48:42 up 4:12, 1 user, load average: 25.25, 23.14, 23.37
$ cat /proc/loadavg
25.72 23.19 23.35 42/3411 43603
对指标的解释:
- 如果平均值是 0.0,那说明系统处于空闲状态。
- 如果 1 分钟内的平均负载高于 5 分钟和 15 分钟,那说明负载正在升高。
- 如果 1 分钟内的平均负载低于 5 分钟和 15 分钟,那说明负载正在降低。
- 如果数值高于 CPU 数量,那可能有性能问题。
由这三个数值,你可以判断出负载在升高或降低。单个数值也有参考意义,比如企业云服务的伸缩可以据此作参考。单个数值23-25没有意义,有了其他信息比如 CPU 数量,你才能判断 CPU 是否处于瓶颈。分析性能,我通常会用一些其它指标来辅助分析,而不是在平均负载这一数值上死磕。
历史
最原始的平均负载只计算对 CPU 的需求:运行进程数量+就绪进程数量。在 1973 年 8 月的RFC 546 TENEX Load Averages有一个漂亮的解释:
[1] The TENEX load average is a measure of CPU demand. The load average is an average of the number of runnable processes over a given time period. For example, an hourly load average of 10 would mean that (for a single CPU system) at any time during that hour one could expect to see 1 process running and 9 others ready to run (i.e., not blocked for I/O) waiting for the CPU.
翻译:
TENEX 平均负载是对 CPU 需求的度量。平均负载是一段时间内可运行进程的平均数量。例如在单核系统上,一小时内平均负载是 10,说明在这一小时内的任意的时刻都可以看到有 1 个进程在运行,另外 9 个处于就绪态(就绪不是指阻塞于 I/O)。
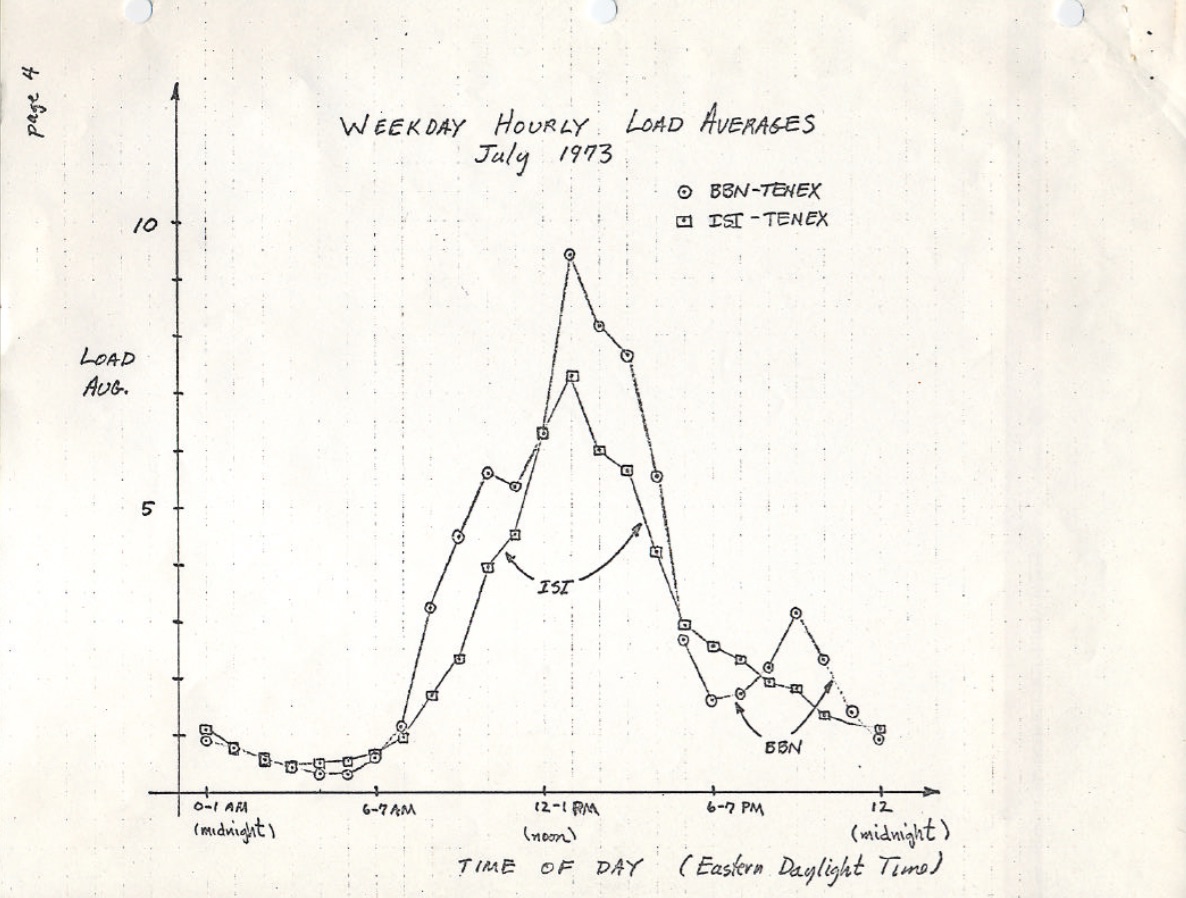
这个版本的RFC 546有一张来自 1973.7 的扫描手绘图,显示系统负载指标已经使用了数十年:
TENEX的源码现在还能找到,以下是一段 DEC 汇编语言的摘录:
NRJAVS==3 ;平均负载的数量
GS RJAV,NRJAVS ;活跃进程的指数平均值
[...]
;更新可运行任务的平均数量
DORJAV: MOVEI 2,^D5000
MOVEM 2,RJATIM ;指定下次更新的时刻
MOVE 4,RJTSUM ;当前时刻 NBPROC+NGPROC 的积分值,对于离散函数,此处积分为求和
SUBM 4,RJAVS1 ;与上个值的差值
EXCH 4,RJAVS1
FSC 4,233 ;FLOAT IT
FDVR 4,[5000.0] ;过去 5000ms 内的平均值
[...]
;指数计算数组 EXP(-T/C),其中 T=5s
EXPFF: EXP 0.920043902 ;C = 1 MIN
EXP 0.983471344 ;C = 5 MIN
EXP 0.994459811 ;C = 15 MIN
Linux 源码里也硬编码了 1 分钟、5 分钟和 15 分钟的常量。以下是include/linux/sched/loadavg.h的代码摘录:
#define EXP_1 1884 /* 1/exp(5sec/1min) as fixed-point */
#define EXP_5 2014 /* 1/exp(5sec/5min) */
#define EXP_15 2037 /* 1/exp(5sec/15min) */
三个数值
这三个数值代表公式会分别计算 1 分钟、5 分钟和 15 分钟内的平均负载,采样间隔为 5 秒。可换算成公式后,你会发现它们不是真的在计算平均值,更不需要连续采样 1 分钟、5 分钟和 15 分钟。汇编可读性差,让我们换成等价的 python 伪代码就一目了然:
e_1 = 0.920043902
e_5 = 0.983471344
e_15 = 0.994459811
e = e_1
s = 0
ls = [0]
for i in range(num):
s = (1-e) * 1 + e * s
ls.append(s)
print(ls[-1])
# 如果 num = 12,即 12*5=60s
# 那 ls[-1] == 0.6321230185169127
这是一种离散化的指数平滑法,1, 5, 15 仅是在公式计算不同的指数常量,公式每个采样周期迭代计算,所得是估计值。
拿一个单核空闲系统做实验,从 0 时刻起启动一个单线程 CPU 跑满的任务,那 60 秒后, 1 分钟平均负载显示约为 0.62,与上述伪代码理论计算值 0.63 相当。如果负载一直持续,最终 1 分钟平均负载为 1。
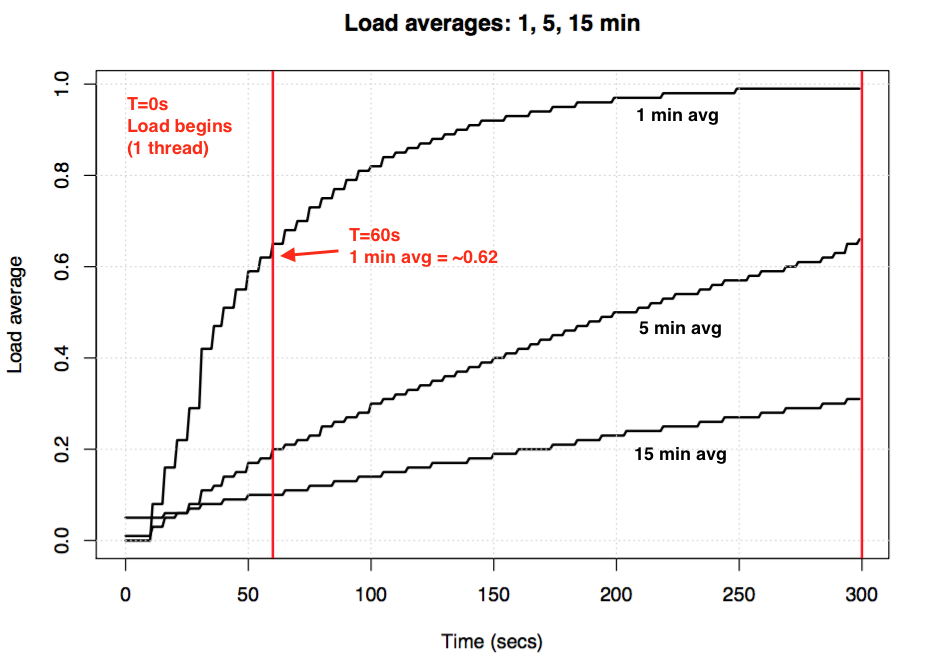
更多公式和实验的讨论,请参考 Dr. Neil Gunther 的文章 How It Works,也可以参考 Linux 源码中的注释。
Linux 不可中断任务
当平均负载指标第一次出现在 Linux 上时,和其它操作系统一样,它只反映了系统对 CPU 的需求。然而不久之后,Linux 把处于不可中断状态(TASK_UNINTERRUPTIBLE或nr_uninterruptible)的任务数量也纳入其中。阻塞于磁盘 I/O 和某些锁的进程即为不可中断进程,这些进程不能被信号量打断。在ps和top命令中,这些进程被标注为D状态,ps(1) 帮助文档中称之为“不可中断睡眠(通常是IO)”。
加入不可中断状态意味着若磁盘(或者 NFS)I/O 工作负载升高,测量的系统负载也会升高。对来自其它操作系统阵营的使用者,这无疑会给他们误解。
为什么?为什么 Linux 要这么做?
有数不清的文章指出了 Linux 系统负载的多面性,但无一解释这么做的动机。我猜测,Linux 这么做是想从总体上反映系统需求。
不可中断任务的起源
该改动早于 2005 年,2005 年以前,Linux 并不是由 git 管理的,所以没有 git commit history 来确认当时合入的动机。我在 oldlinux.org 备份的邮件列表中翻到了这么一封邮件:
From: Matthias Urlichs <urlichs@smurf.sub.org>
Subject: Load average broken ?
Date: Fri, 29 Oct 1993 11:37:23 +0200
The kernel only counts "runnable" processes when computing the load average.
I don't like that; the problem is that processes which are swapping or
waiting on "fast", i.e. noninterruptible, I/O, also consume resources.
It seems somewhat nonintuitive that the load average goes down when you
replace your fast swap disk with a slow swap disk...
Anyway, the following patch seems to make the load average much more
consistent WRT the subjective speed of the system. And, most important, the
load is still zero when nobody is doing anything. ;-)
kernel/sched.c.orig Fri Oct 29 10:31:11 1993
+++ kernel/sched.c Fri Oct 29 10:32:51 1993
@@ -414,7 +414,9 @@
unsigned long nr = 0;
for(p = &LAST_TASK; p > &FIRST_TASK; --p)
- if (*p && (*p)->state == TASK_RUNNING)
+ if (*p && ((*p)->state == TASK_RUNNING) ||
+ (*p)->state == TASK_UNINTERRUPTIBLE) ||
+ (*p)->state == TASK_SWAPPING))
nr += FIXED_1;
return nr;
}
--
Matthias Urlichs \ XLink-POP N|rnberg | EMail: urlichs@smurf.sub.org
Schleiermacherstra_e 12 \ Unix+Linux+Mac | Phone: ...please use email.
90491 N|rnberg (Germany) \ Consulting+Networking+Programming+etc'ing 42
改动是由 Matthias 引入,最终在Linux 0.99.14中合入。从邮件中可以确认,平均负载的这一改动就是为了反映对系统资源的总体需求:即 CPU 平均负载 --> 系统资源负载。
27 年前,Matthias 用慢速 swap 磁盘做例子是合理的:swap 磁盘拖慢了系统性能,那平均负载这一指标理应升高,然而按当时的计算方法,平均负载反而会降低,因为该指标只计入了处于可运行状态的任务,而慢速 swap 磁盘导致的大量任务不可运行没有被统计在内。这显然有悖常理,所以 Matthias 提交了这一补丁。
如今的不可中断任务
除了磁盘 I/O, CPU 外还有别的原因会导致 Linux 平均负载升高吗?是的,虽然我猜测在 1993 年时,还没有其它代码路径会设置 TASK_UNINTERRUPTIBLE。在Linux 0.99.14,有 13 条代码路径会直接设置TASK_UNINTERRUPTIBLE或TASK_SWAPPING(后来 Linux 移除了 swap 状态)。而在 2017 年的Linux 4.12,则有 400 多种可能会设置TASK_UNINTERRUPTIBLE,包括一些锁原语。
既然可能性如此之多,是不是每种都和系统负载有关?本文作者给 Matthias 发邮件询问了此事,Matthias 则回复:
"The point of "load average" is to arrive at a number relating how busy the system is from a human point of view. TASK_UNINTERRUPTIBLE means (meant?) that the process is waiting for something like a disk read which contributes to system load. A heavily disk-bound system might be extremely sluggish but only have a TASK_RUNNING average of 0.1, which doesn't help anybody."
翻译如下:
“平均负载”的意义在于从人的角度描述系统的繁忙程度。TASK_UNINTERRUPTIBLE 意味着(过去意味着?)进程在等待某些资源,比如读磁盘,这些行为会增加系统负载。疯狂读磁盘的系统性能奇差,但此刻 TASK_RUNNING 任务的平均数量只有 0.1,单看这个值也就没参考意义了。
Matthias 仍认为这么计算是对的,不过给出的解释仍和 93 年相同。
但是现在有更多的情况会让任务处于TASK_UNITERRUPTIBLE状态,是否应该改进计算平均负载的算法,剪去多余分支呢?Linux 调度器维护者 Peter Zijstra 给出了一种解法:用task_struct->in_iowait替换TASK_UNITERRUPTIBLE,这样平均负载仍然反映对 CPU 和磁盘的需求。
但绕了这么一大圈,真的测到我们想要的了吗?我们是要反映对系统线程的需求,还是反映对物理资源的需求?如果是前者,那由于不可中断锁而阻塞的线程也应纳入统计,因为系统需要这些线程,它们并不是空闲的。
为了更好地理解不可中断的代码路径,首先我们需要一种度量进程各阶段实际耗时的方法,然后才能量化每个场景所花的时间,检验平均负载这一指标能否切合实际。
测量不可中断任务
下图是一个生产环境服务器的 off-CPU 火焰图(On-CPU 是任务在CPU上运行的消耗,off-CPU 就是任务由于某种原因阻塞的消耗,如等待IO,等待锁,等待定时器,等待内存页面的swap等),测量持续了 60 秒,并过滤出了处于TASK_UNINTERRUPTIBLE的任务的内核栈:
完整的栈显示出来就像一把火焰,你可以点击放大查看火焰图的细节。x 轴上的长度正比于阻塞 off-CPU 的时间,顺序是随机的。上图显示 60s 内只有 926ms 的时间处于不可中断睡眠,只给平均负载增加了 0.015。其中大部分是 cgroup 调用,系统本身并没有太多磁盘 I/O。
接下来这张图更有趣,测量只持续了 10 秒:
图中用洋红色高亮的栈帧均是rwsem_down_read_failed(),加起来增加了 0.3 的平均负载。让我们摘录rwsem_down_read_failed()的部分代码,可以看到其在获取锁时给任务设置了TASK_UNINTERRUPTIBLE状态。
/* wait to be given the lock */
while (true) {
set_task_state(tsk, TASK_UNINTERRUPTIBLE);
if (!waiter.task)
break;
schedule();
}
Linux 锁有不可中断(mutex_lock(), down())和可中断(mutex_lock_interruptible(), down_interruptible())两个版本,可中断版本允许信号绕过锁机制唤醒阻塞的任务。通常不可中断锁的睡眠时间很短,一般不影响平均负载,但在这个例子中,增加了 0.30。如果该值在上一个数量级,那就有必要做深入的性能分析,以减少锁竞争来降低平均负载。
这么看来,那些阻塞于不可中断锁上的线程也会造成 Linux 软件资源的紧缺,计算负载时不能只关注硬件资源(CPU,磁盘I/O)。
分解 Linux 平均负载
平均负载只是一个数,能否分解出其中的各个部分呢?看这个例子:在一个 8 核的系统上,用tar解压文件,一共用时数分钟,大部分时间阻塞于读磁盘。然后用pidstat, iostat, uptime在三个窗口同时收集性能信息:
terma$ pidstat -p `pgrep -x tar` 60
Linux 4.9.0-rc5-virtual (bgregg-xenial-bpf-i-0b7296777a2585be1) 08/01/2017 _x86_64_ (8 CPU)
10:15:51 PM UID PID %usr %system %guest %CPU CPU Command
10:16:51 PM 0 18468 2.85 29.77 0.00 32.62 3 tar
termb$ iostat -x 60
[...]
avg-cpu: %user %nice %system %iowait %steal %idle
0.54 0.00 4.03 8.24 0.09 87.10
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
xvdap1 0.00 0.05 30.83 0.18 638.33 0.93 41.22 0.06 1.84 1.83 3.64 0.39 1.21
xvdb 958.18 1333.83 2045.30 499.38 60965.27 63721.67 98.00 3.97 1.56 0.31 6.67 0.24 60.47
xvdc 957.63 1333.78 2054.55 499.38 61018.87 63722.13 97.69 4.21 1.65 0.33 7.08 0.24 61.65
md0 0.00 0.00 4383.73 1991.63 121984.13 127443.80 78.25 0.00 0.00 0.00 0.00 0.00 0.00
termc$ uptime
22:15:50 up 154 days, 23:20, 5 users, load average: 1.25, 1.19, 1.05
[...]
termc$ uptime
22:17:14 up 154 days, 23:21, 5 users, load average: 1.19, 1.17, 1.06
最后是 60 秒内的 off-CPU 火焰图:
uptime 显示倒数一分钟时系统负载为 1.25,最后一分钟的平均负载为 1.19。
让我们来尝试分解:
- 0.33 来自 tar 的 CPU 时间(pidstat)
- 41164/60000=0.69 来自 tar 的不可中断磁盘读(火焰图)
- (3684+3102)/60000=0.11 来自内核的不可中断磁盘I/O - 刷新磁盘(火焰图的最左两个高峰)
- 0.04 来自其它任务(iostat 统计出总的 user+system 时间 - tar 的 CPU 时间)
代入指数平滑算法:(0.33+0.69+0.11+0.04)*0.62 + 1.25*0.38 = 1.17*0.62 + 1.25*0.38 = 1.2。非常接近 uptime 测得的 1.19。
这个系统只有一个主要线程 tar,和其它一些辅助和内核线程,Linux 报告 平均负载 1.19 是合理的。如果只测量CPU 平均负载,那就是0.33+0.04=0.37,并没有反馈出系统压力真正的来源。
让 Linux 平均负载有意义
- 在 Linux 系统上,平均负载是系统平均负载,统计的对象多种多样:运行状态的线程和因为某些原因等待运行的线程(CPU、磁盘、不可中断锁)。优点是能对整个系统做度量,方便使用者从整体把握性能状态。
- 在其它操作系统上,平均负载是CPU 平均负载,测量的是可运行线程数量。优点是易于理解,看到指标就知道问题在哪。
什么是“好”或“坏”的平均负载
- 平均负载对系统监控有参考意义:当数值超过某一绝对值时,应用延迟必定很高,性能会出现瓶颈,但这个绝对值不具备通用性。
- 平均负载是一段时间内(> 1min)的平均值,同样 1 的平均负载即可能是持续稳定的负载,也可能是一个突发的高负载。
- 其它操作系统中的 CPU 平均负载可以按这个公式归一化:
CPU 平均负载/CPU 个数。 - 不同应用场景对系统延迟的容忍度不同。比如双核 CPU 邮件服务器的归一化值约为 11-16,但邮件协议不是即时通信协议,实时性不高,用户不会抱怨。(而其它应用用户所能容忍的归一化值不会高于 2)
- 在 Linux 中,平均负载包含
TASK_UNINTERRUPTIBLE,所以不能使用归一化的值。
更好的指标
在 Linux 系统上,光靠平均负载不能定位问题,这里介绍介绍一些其它指标。
- 查看每个 CPU 的利用率,
mpstat -P ALL 1 - 查看每个进程的 CPU 利用率,
top,pidstat 1 - 查看每个线程的调度延迟,
/proc/PID/schedstats,delaystats,perf sched - 查看 CPU 调度队列的长度,
vmstat 1的r列
结论
在 1993 年,一位 Linux 工程师发现原先的平均负载斌不直观,随即将定义从“CPU 平均负载”永远地改成了“系统平均负载”。新算法把不可中断任务也纳入其中,以便反映出对磁盘资源的需求。算法仍然使用指数平滑法估计 1, 5 和 15 分钟内的负载,通过这三个值可以判断负载升高还是降低。
随着 Linux 内核的发展,不可中断的代码路径不断丰富,现在还包含了不可中断锁原语等。但 93 年的算法不需要改变,因为系统负载含义丰富了,多出来的代码路径正好能覆盖这些负载。
本文删减了作者的原文,一些定位系统负载问题的方法可以翻阅上两篇文章。
参考文献
- Saltzer, J., and J. Gintell. “The Instrumentation of Multics,” CACM, August 1970 (explains exponentials).
- Multics system_performance_graph command reference (mentions the 1 minute average).
- TENEX source code (load average code is in SCHED.MAC).
- RFC 546 "TENEX Load Averages for July 1973" (explains measuring CPU demand).
- Bobrow, D., et al. “TENEX: A Paged Time Sharing System for the PDP-10,” Communications of the ACM, March 1972 (explains the load average triplet).
- Gunther, N. "UNIX Load Average Part 1: How It Works" PDF (explains the exponential calculations).
- Linus's email about Linux 0.99 patchlevel 14.
- The load average change email is on oldlinux.org (in alan-old-funet-lists/kernel.1993.gz, and not in the linux directories, which I searched first).
- The Linux kernel/sched.c source before and after the load average change: 0.99.13, 0.99.14.
- Tarballs for Linux 0.99 releases are on kernel.org.
- The current Linux load average code: loadavg.c, loadavg.h
- The bcc analysis tools includes my offcputime, used for tracing TASK_UNINTERRUPTIBLE.
- Flame Graphs were used for visualizing uninterruptible paths.