知乎轮带逛 - 定向爬取轮子哥赞过的妹子图
前言
轮带逛,是指跟着轮子哥的知乎动态很容易找到高质量妹子图。然而知乎动态管理和搜索都不友好,如果手工翻阅动态工作量很大,所以写了一个脚本,用于找出那些妹子图片。
这是脚本的源码链接
GitHub 上已经有一些知乎的第三方 API,如 zhihu-py3 和 zhihu-python 。
但我想用异步写,且定制性高,所以还是从头造个轮子。
页面分析
知乎登陆过程分析
上述 GitHub 知乎的 API 都是使用邮箱、密码、验证码来登陆的,现在知乎支持只使用邮箱/手机号、密码来登陆。虽然老接口仍然可用,但新方法更便捷。
因为登陆过程会有 Redirects,所以建议打开 Firebug 的 Persist,或者是使用 Burpsuite 之类的代理来捕获 https 数据流量。
以下是使用邮箱登陆时关键的两个请求。

以下为提交密码的请求,可以看到 POST 四个参数。
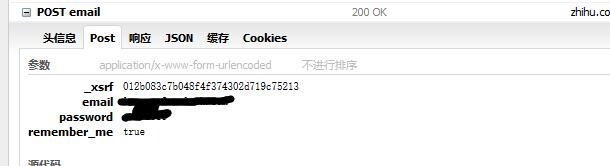
remember_me 为记住我,而 _xsrf 是在登陆页面 html 代码的隐藏参数。
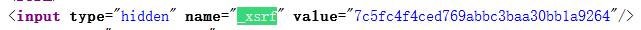
在获取用户更多动态时需要将 _xsrf 作为参数之一提交。但是这里有个小坑,这里获取的 _xsrf 值并不等于获取动态时提交的 _xsrf。实际上经过测试,在登陆时也根本不需要提交这个 _xsrf 参数。个人猜测这是旧接口的遗留代码。
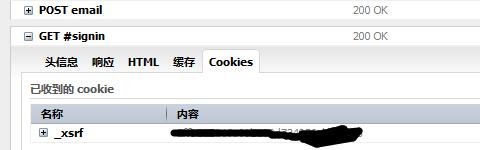
那么之后获取更多动态时的 _xsrf 来自哪呢?它藏在 cookies 中。然而知乎的 cookies 并不是一次性获取完毕,如下图所示,登陆完毕只拿到了五个项。(事先把知乎的 cookies 清空)
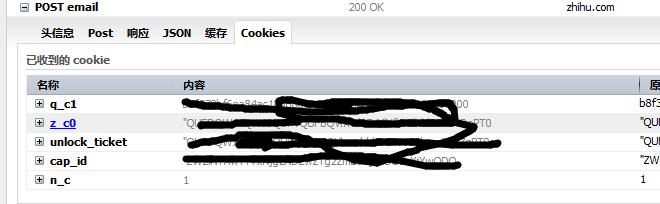
而紧接着的第二个 GET 请求,才会拿到这个关键的 _xsrf cookies。
至此,登陆完毕。
知乎用户新动态分析
分析可借助浏览器调试工具查看,这里总结如下。
- 每个用户动态位于 ('div', class_='zm-profile-section-item zm-item clearfix');
- 上述 div 标签中,若 'data-type-detail' == 'member_voteup_answer',则为该用户送出的赞;
- 上述 div 标签中,data-time 属性的值需作为获取更多状态时作为 start 提交;
- 每个回答在点击之前"显示全部"之前是隐藏的,位于 ('textarea', class_='content hidden'),隐藏内容被转义过;
- 每个回答的评论链接位于 ('div', class_='zm-item-answer')。
获取知乎回答的评论
GET 上述的评论链接,会返回一个 json 数据。json['paging'] 中为评论总数、每页评论数、当前页。json['data'] 为评论数据。
模拟点击“更多”,获取更多动态
以 cookies 中的 _xsrf 和当前最后一个 data-time 为参数 POST,即可获得更多状态。返会的是 html 代码,然后重复上述步骤直到没有更多状态为止。
程序及算法
其实算法很简单。所有轮带逛的回答评论中都有类似“轮带逛、文明观球、营养快线”等关键字,只要符合这个规律,就可以判断出这条动态是我们的目标。
我采用 Python3.5 原生的 asyncio 来实现异步,用 aiohttp 编写了所有的底层 GET/POST 请求。一共分为三个任务:crawl_voteup_answer、download_image、monitor,任务之间通过队列通信。
\
| | |
crawl_voteup_answer --> 登陆 --> 找到赞 --> 分析评论 --> 获取图片链接 -/
|
queue.put(url)
download_image <-- queue.get(url)
monitor 任务中主要是打印队列中等待的链接个数。另外,大约每隔 200s 会让整个爬虫停止 20s,以避免知乎可能的反爬虫措施。
结论
我用以下的参数,花了两个小时爬完了轮子哥的所有动态。
more_interval = 1 # 点击更多的时间间隔
comment_interval = 0.2 # 获取评论的时间间隔
img_interval = 0.2 # 下载图片的时间间隔
一共找到 3669 个妹子图片,其中有效的估计为 85%。而且根据终端的打印过程粗略分析,轮子个在 2015.6 之前还是很正经的,专注于技术问题,而在 2015.6 之后大约有 3000 个妹子图。